Datengetriebene Personalisierung – Warum nicht von Netflix & Co. lernen?
Fünf Verlage starten mit SCHICKLER und der dpa in die Data Science-Zukunft. In 2021 soll die Initiative auf 15 Verlage anwachsen. Die ganze Branche profitiert.
Die meisten erfolgreichen Digital-Medien setzen Künstliche Intelligenz in der Personalisierung und Ausspielung ihrer Inhalte ein. Nur nicht Verlage, vielleicht mit Ausnahme einiger Leuchttürme wie der New York Times. Statt ihre Angebote auf die User-Interessen anzupassen, folgen die meisten Newsrooms noch dem alten Paradigma „ein Angebot für alle“. Und das in einer Welt, in der die individuellen Interessen so ausgeprägt sind wie nie zuvor. Die Folge: Digitale Abonnements haben eine geringere Haltbarkeit, weil die Nutzer enttäuscht werden. Bei regionalen Tageszeitungen in Deutschland sind zwei von drei Abonnenten nach einem Jahr wieder weg.
Damit sich das ändert, haben SCHICKLER und dpa die DRIVE-Initiative gegründet. Die Bezeichnung steht für Digital Revenue Initiative. In der Pilotphase mit dabei sind die Regionalverlage aus Regensburg, Freiburg, Aachen, Münster und Dortmund.
Die Grundidee von DRIVE ist einfach: Alle Verlage legen ihre Daten zusammen. So entsteht eine kritische Datenmenge, auf denen selbstlernende Algorithmen trainiert werden können. Die Kosten für Data Science und Projektmanagement teilen sich alle Verlage, ebenso wie die Ergebnisse. SCHICKLER stellt die Data Science – Kompetenz und das Projektmanagement zur Verfügung, die dpa steht für die größte Datenbank an Inhalten und für redaktionelle Kompetenz.
Auch das technische Konzept ist schnell erklärt. Über Schnittstellen werden Primärdaten aus den Verlagen auf eine Cloud-Datenbank überstellt. Darunter alle Artikel und User Events, also Informationen, wie sich die User verhalten haben. Die Installation der Schnittstellen dauert nur ein bis zwei Tage. Schon heute laufen jeden Tag über sechs Millionen Datensätze in das System. Die Datenbank wird bis Ende des Jahres 320 Mio. User-Events umfassen. Die DRIVE-Algorithmen greifen automatisch auf diesen Datenschatz zu. Aber auch jeder Projektteilnehmer kann über simple Analysetools Auswertungen durchführen.
Erste Erkenntnisse
Eine erste Erkenntnis: Weniger als 5% der User von Nachrichten-Angeboten sind loyale Nutzer. Der Rest, also über 95% der User, nutzen eine Nachrichten-Webseite weniger als 10 Minuten in vier Wochen. Die Redaktion muss sich darauf konzentrieren, die loyalen Nutzer zu treuen Abonnenten zu entwickeln. Die heute gängigen Artikels-Scores und Redaktions-Zielgrößen stellen jedoch meist die absolute Reichweite in den Vordergrund. Damit verzerren die 95% Zufallsnutzer das Bild vollständig. Im schlimmsten Fall führen die Artikel-Scores zu kompletten Fehlsteuerungen.
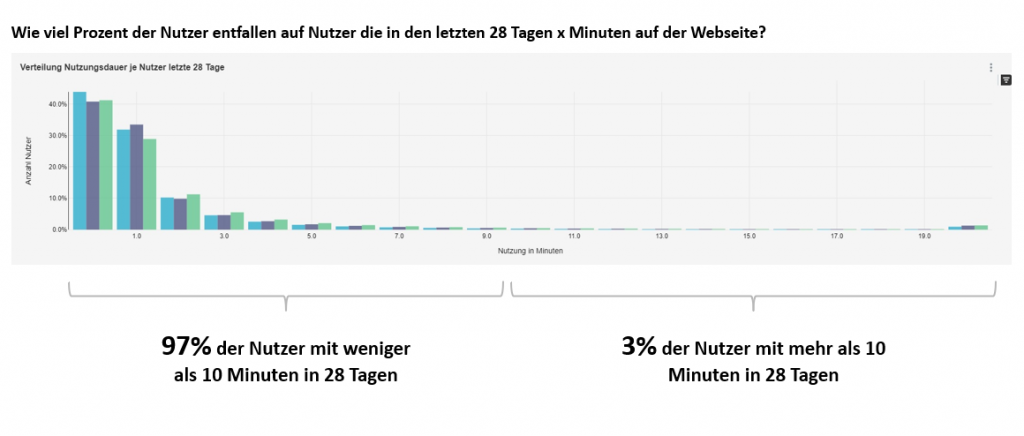
Das Ziel von DRIVE ist es daher, Algorithmen zu trainieren, das Nutzerverhalten zu analysieren. Gleichzeitig klassifizieren sie den Content. Auf dieser Basis können die Inhalte automatisch auf den Nutzer personalisiert werden, und zwar entsprechend der Redaktionsstrategie, die jeder Verlag für sich entscheidet.
Auch eine Besonderheit des Projekts: Es herrscht vollständige Transparenz. Jeder kann alle Daten sehen und hat Zugriff auf alle Auswertungen. Schubladendenken gehört der Vergangenheit an, im Wettbewerb mit Google & Co. müssen die Verlage ihre Stärken bündeln. Alle Teilnehmer können ihre individuellen Analyseanforderungen einbringen. Da sich viele Themen ähneln, müssen sie häufig nur einmal beantwortet werden. So gewinnen wir Geschwindigkeit.
Ihr Medienhaus bei DRIVE?
Verläuft die Pilotphase bis Ende 2020 erfolgreich, wollen wir 10 weitere Verlage aufnehmen. Die ersten Gespräche laufen bereits. Denn auch im Data Science gilt das alte Motto: je mehr, desto besser.
Ansprechpartner für die DRIVE-Initiative sind Rolf-Dieter Lafrenz (SCHICKLER), Dr. Christoph Mayer (SCHICKLER) und Meinolf Ellers (dpa).
Rolf-Dieter Lafrenz (Partner SCHICKLER)
Interessiert? Bleiben Sie mit dem SCHICKLER.essentials Newsletter auf dem Laufenden!






